The next block of code is:
abort() {
{ if [ "$#" -eq 0 ]; then cat -
else echo "rbenv: $*"
fi
} >&2
exit 1
}
Shell Functions
Here we declare a function named abort.
The first thing I notice is the exit 1 at the end. We’re returning a non-zero (i.e. failure-mode) exit status at the end of the function, which makes sense for a function named abort. This also implies that, if we see a call to abort, we’re dealing with a sad-path scenario.
Before that, however, we see a block of code surrounded with curly braces, with >&2 appended to the end:
{ if [ "$#" -eq 0 ]; then cat -
...
} >&2
I’m a bit thrown off by this syntax here. Why is this code…
if [ "$#" -eq 0 ]; then cat -
else echo "rbenv: $*"
fi
…wrapped inside this code?
{
...
} >&2
Let’s start on the outside and work our way in. What is the function of the curly braces?
Output Grouping
I Google “curly braces bash”, and the first result I get is this one from Linux.com, which sounds promising. I scan through the article looking for syntax which is similar to what we’re doing, and along the way I learn some interesting but unrelated stuff (for instance, echo {10..0..2} will print every 2nd number from 10 down to 0 in your terminal).
Finally I get to the last section of the article, called “Output Grouping”. It’s here that I learn that “…you can also use { ... } to group the output from several commands into one big blob.”
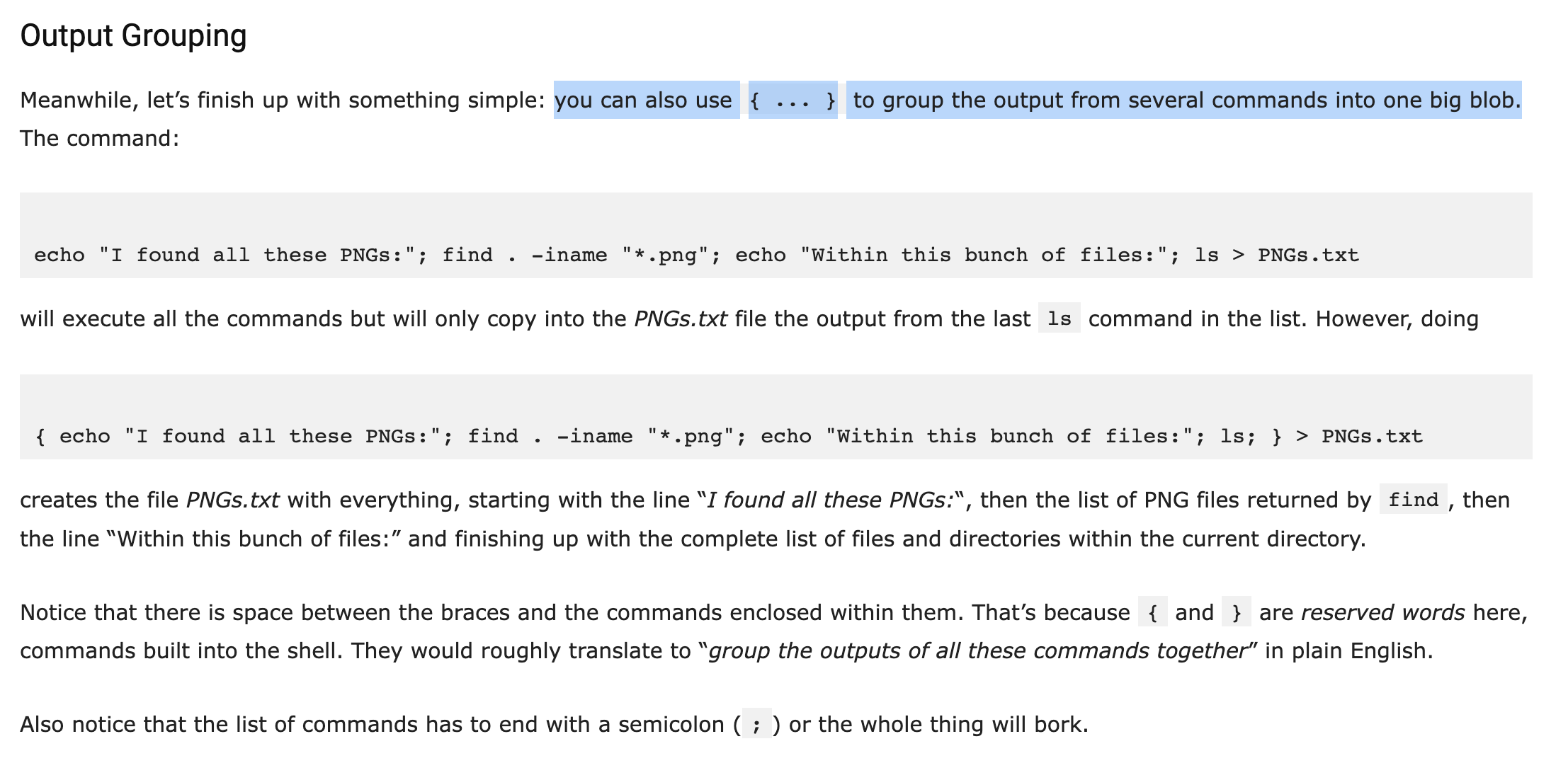
Cool, mystery solved- we’re capturing the output of everything inside the curly braces, so we can output it all together (instead of just the last statement).
Redirection
Next question- what is >&2 at the end there?
I Google “>&2 bash”. The first result is from StackExchange:
Using > to redirect output is the same as using 1>. This says to redirect stdout (file descriptor 1).
Normally, we redirect to a file. However, we can use >& to redirect to stdout (file descriptor 1) or stderr (file descriptor 2) instead.
Therefore, to redirect stdout (file descriptor 1) to stderr (file descriptor 2), you can use >&2
So we’re capturing the output of whatever the curly braces send to stdout, and redirecting it to stderr. I happen to know from prior experience that stdout is short-hand for “standard out”, and stderr means “standard error”. I have a vague notion of what these terms mean, but I’m not sure I could verbalize what they actually refer to.
I Google “stdout stdin stderr” and get this link as the first result. From reading it, I learn that:
- these three things are called “data streams”.
- “…a data stream is something that gives us the ability to transfer data from a source to an outflow and vice versa. The source and the outflow are the two end points of the data stream.”
- “…in Linux all these streams are treated as if they were files.”
- “…linux assigns unique values to each of these data streams:
- 0 = stdin
- 1 = stdout
- 2 = stderr”
The cool thing here is that, if we redirect the output of our abort function to stderr, then someone else can pick up where we left off, and send the output of their stderr anywhere they want.
A website called Guru99 seems to have some good content on redirection. For example:

Here we’re taking the output of the ls -al command (which would normally be sent to the screen via stdout) and redirecting it to a file instead via the > character.
Piping
But wait, I’ve also previously seen the | character used to send output from one place to another. Why are we using > here instead?
I Google “difference between < > | unix”, but the special characters confuse Google and I get a bunch of irrelevant results. I try my luck with ChatGPT, with the understanding that I’ll need to double-check its answers after:

ChatGPT tells me that > and < are used for “redirection”, i.e. sending output to or pulling input from a file. On the other hand, | is used for “piping” output to a command.
Based on this, I Google “difference between redirection and piping unix”, and one of the first results I get is this StackExchange post which says something quite similar to ChatGPT:

I like that this person explains how it’s possible (but clunky) to use > to redirect to a file, and then use < to grab the content of that file and redirect it to another command. So instead, we just use | instead. That somehow makes things much clearer for me.
So what exactly is the output that we’re reirecting to stderr? Let’s move on to the code inside the curlies.
The code inside the curly braces is:
if [ "$#" -eq 0 ]; then cat -
else echo "rbenv: $*"
fi
Counting Parameters
First question- what does $# evaluate to? According to StackOverflow:
echo $#outputs the number of positional parameters of your script.
So [ "$#" -eq 0 ] means “if the number of positional parameters is equal to zero”? Let’s test that with an experiment.
Experiment- counting parameters
I write the following script, named foo:
#!/usr/bin/env bash
if [ "$#" -eq 0 ]; then
echo "no args given"
else
echo "$# args given"
fi
When I run it with no args, I see:
$ ./foo
no args given
When I run it with one arg, I see:
$ ./foo bar
1 args given
And when I run it with multiple args, I see:
$ ./foo bar baz
2 args given
I think we can conclude that [ "$#" -eq 0 ] returns true if the number of args is equal to zero. But whose positional parameters are we talking about- the abort function’s params, or rbenv’s params?
I try wrapping my experiment code in a simple function definition:
#!/usr/bin/env bash
function myFunc() {
if [ "$#" -eq 0 ]; then
echo 'no args given';
else
echo "$# args given";
fi
}
echo "$# args given to the file";
myFunc foo bar baz buzz
I’m passing 4 args to myFunc, but I’m planning to call my script with only 2 args, with the intention that:
- If
$#refers to the number of args sent to the file, then we should see the same counts from theechostatements outside vs. inside the function. - But if
$#refers to the # of args sent tomyFunc, then we’ll see different counts for these twoechostatements.
When I run the script file with multiple args, I see:
$ ./foo bar baz
2 args given to the file
4 args given
We see different counts for the # of args passed to the file vs. to myFunc. So when $# is inside a function, it must be refer to the # of args passed to that same function.
Reading from stdin
Back to our block of code:
{ if [ "$#" -eq 0 ]; then cat -
... } >&2
So if the number of args we pass to abort is 0, then we execute cat -. What is cat -?
I type help cat in my terminal, and get the following:
The
catutility reads files sequentially, writing them to the standard output. The file operands are processed in command-line order. If file is a single dash (‘-‘) or absent,catreads from the standard input.
OK, so if there are no args passed to abort, then we read from standard input. Interesting. Based on what we learned earlier about redirection and piping, I wonder if the caller of the abort function is piping its stdout to the stdin here, so that abort can read it via cat -.
I search for | abort in this file, and I find this block of code:
{ rbenv---version
rbenv-help
} | abort
It looks like we’re doing something similar with curly braces (i.e. capturing the output from a block of code) and piping it to abort. So, yeah, it looks like we were right about the purpose of cat -. It lets us capture arbitrary input from stdin and print it to the screen.
Let’s try to replicate that and see what happens:
#!/usr/bin/env bash
function foo() {
{
if [ "$#" -eq 0 ]; then cat -
fi
} >&2
exit 1
}
echo "Whoops" | foo
When I run this script, I see:
$ ./foo
Whoops
Gotcha- the logic inside the if clause is meant to allow the caller of the abort function to send text into the function via piping.
Listing any and all arguments
Last bit of code inside abort():
else echo "rbenv: $*"
What does $* do? This time, it’s O’Reilly to the rescue:

So $* expands to a single string containing all the arguments passed to the script. We can verify that by writing our own simple script:
#!/usr/bin/env bash
echo "args passed in are: $*"
When we call it, we get:
$ ./foo bar baz
args passed in are: bar baz
No surprises here.
While we’re at it, let’s try a similar experiment that we did with cat -, but with the “else” case here. Going back into my “foo” script, I make the following changes:
- I add an identical
elseclause to ourfoofunction, and - I replace the previous pipe invocation of
foowith a new one that passes a string as a parameter:
#!/usr/bin/env bash
foo() {
{ if [ "$#" -eq 0 ]; then cat -
else echo "rbenv: $*"
fi
} >&2
exit 1
}
foo "oopsy-daisies"
Running the script gives us:
$ ./foo
rbenv: oopsy-daisies
So it just concatenates “rbenv: “ at the front of whatever error message you pass it.
So to sum up the “abort” function:
- if you don’t pass it any string as a param, it assumes you are piping in the error, and it reads from STDIN and prints the input to STDERR. Otherwise…
- It assumes that whatever param you passed is the error you want to output, and…
- It prints THAT to STDERR.
- Lastly, it terminates with a non-zero exit code.
We were lucky here, because the abort function is called throughout the rbenv file, and we were able to use those examples in understanding how the function worked. It’s not always possible to use this strategy, but when it IS possible, it’s a good tool for our toolbelt.
Let’s move on.