Again, let’s start with the test file, help.bats.
Tests
Showing common commands
After the shebang and the test_helper load, the first spec is:
@test "without args shows summary of common commands" {
run rbenv-help
assert_success
assert_line "Usage: rbenv <command> [<args>]"
assert_line "Some useful rbenv commands are:"
}
This is the happy-path test:
- We run the command file.
- We assert that the exit code is 0.
- We also assert that the “Usage:” and “Some useful rbenv commands” lines both appear in STDOUT.
This is what appears when I type rbenv help in my console, a-la this first test case:
$ rbenv help
Usage: rbenv <command> [<args>]
Some useful rbenv commands are:
commands List all available rbenv commands
local Set or show the local application-specific Ruby version
global Set or show the global Ruby version
shell Set or show the shell-specific Ruby version
install Install a Ruby version using ruby-build
uninstall Uninstall a specific Ruby version
rehash Rehash rbenv shims (run this after installing executables)
version Show the current Ruby version and its origin
versions List installed Ruby versions
which Display the full path to an executable
whence List all Ruby versions that contain the given executable
See `rbenv help <command>' for information on a specific command.
For full documentation, see: https://github.com/rbenv/rbenv#readme
Sad path- specifying an invalid command
Next test case:
@test "invalid command" {
run rbenv-help hello
assert_failure "rbenv: no such command \`hello'"
}
When the user types in an argument for a command that doesn’t exist, RBENV should show an error message and return a non-zero exit code. In this test:
- We run a known-incorrect command (
rbenv hello). - We assert that the exit code is non-zero.
- We also that the feedback “rbenv: no such command…” appears in STDOUT.
For what it’s worth, I get this same result in my terminal:
$ rbenv help foobar
rbenv: no such command `foobar'
Happy path- showing the help results for a known-valid command
Next test case:
@test "shows help for a specific command" {
mkdir -p "${RBENV_TEST_DIR}/bin"
cat > "${RBENV_TEST_DIR}/bin/rbenv-hello" <<SH
#!shebang
# Usage: rbenv hello <world>
# Summary: Says "hello" to you, from rbenv
# This command is useful for saying hello.
echo hello
SH
run rbenv-help hello
assert_success
assert_output <<SH
Usage: rbenv hello <world>
This command is useful for saying hello.
SH
}
This is a pretty big test. Let’s break it up into pieces:
mkdir -p "${RBENV_TEST_DIR}/bin"
Above, we make a directory especially for this test that we’re running.
cat > "${RBENV_TEST_DIR}/bin/rbenv-hello" <<SH
#!shebang
# Usage: rbenv hello <world>
# Summary: Says "hello" to you, from rbenv
# This command is useful for saying hello.
echo hello
SH
We then create a new executable command called rbenv-hello. We add a fake shebang and some usage comments to the file, followed by a command to just echo ‘hello’. Basically just enough fake file content to mimic a real rbenv command file.
Next half of the test is:
run rbenv-help hello
assert_success
We then run rbenv help plus the name of our fake command, assert that the exit code is 0.
assert_output <<SH
Usage: rbenv hello <world>
This command is useful for saying hello.
SH
Lastly, we also assert that the output contains just the usage and summary comments from the file, without the shebang and without the executable logic of the command itself.
One interesting thing I notice is that the line starting with # Summary: is not part of the expected output, but the following line (This command is useful for saying hello.) is part of the output. This implies that the rbenv help command strips the Summary line out. The next test will address why.
Handling missing instruction text
Next test:
@test "replaces missing extended help with summary text" {
mkdir -p "${RBENV_TEST_DIR}/bin"
cat > "${RBENV_TEST_DIR}/bin/rbenv-hello" <<SH
#!shebang
# Usage: rbenv hello <world>
# Summary: Says "hello" to you, from rbenv
echo hello
SH
run rbenv-help hello
assert_success
assert_output <<SH
Usage: rbenv hello <world>
Says "hello" to you, from rbenv
SH
}
This test does something similar to (but not identical to) the previous test. The difference is, this time:
- the fake
hellocommand is missing instruction text below the# Summary:comment, and - the output of
rbenv helpincludes the# Summary:line.
Those two things are related. The Summary line is only included if the detailed explanation text below Summary is missing.
Passing the --usage flag
Next spec:
@test "extracts only usage" {
mkdir -p "${RBENV_TEST_DIR}/bin"
cat > "${RBENV_TEST_DIR}/bin/rbenv-hello" <<SH
#!shebang
# Usage: rbenv hello <world>
# Summary: Says "hello" to you, from rbenv
# This extended help won't be shown.
echo hello
SH
run rbenv-help --usage hello
assert_success "Usage: rbenv hello <world>"
}
In this test:
- We create a command with usage, summary, and extended description info.
- We then run
rbenv helpfor this test command, this time passing the--usageflag. - We then assert that the output only contains the
usageinfo.
To try this for myself, I run rbenv help --usage rehash, assuming that the rehash command would contain usage info. However, it appears that it does not:
$ rbenv help --usage rehash
$
I tried another command (global), and this time it worked:
$ rbenv help --usage global
Usage: rbenv global <version>
We’ll find out later that rbenv help actually inspects the file of the command you pass it, and scrapes the Usage instructions to use as output. The reason this didn’t work with rbenv help rehash was because the rbenv-rehash file doesn’t include any # Usage comments.
Edge case- Usage comments spanning multiple lines
Next test:
@test "multiline usage section" {
mkdir -p "${RBENV_TEST_DIR}/bin"
cat > "${RBENV_TEST_DIR}/bin/rbenv-hello" <<SH
#!shebang
# Usage: rbenv hello <world>
# rbenv hi [everybody]
# rbenv hola --translate
# Summary: Says "hello" to you, from rbenv
# Help text.
echo hello
SH
run rbenv-help hello
assert_success
assert_output <<SH
Usage: rbenv hello <world>
rbenv hi [everybody]
rbenv hola --translate
Help text.
SH
}
In this test:
- We make another test command, this time with a multi-line “Usage” comment.
- We then assert that the
helpoutput includes both the entire “Usage” comment, and the description text, but not the “Summary” text.
So apparently there’s something in rbenv help that is capable of detecting when the Usage comments stop and Summary comments start, even over multiple lines of output.
Edge case- multiple lines of additional help content
Last spec is:
@test "multiline extended help section" {
mkdir -p "${RBENV_TEST_DIR}/bin"
cat > "${RBENV_TEST_DIR}/bin/rbenv-hello" <<SH
#!shebang
# Usage: rbenv hello <world>
# Summary: Says "hello" to you, from rbenv
# This is extended help text.
# It can contain multiple lines.
#
# And paragraphs.
echo hello
SH
run rbenv-help hello
assert_success
assert_output <<SH
Usage: rbenv hello <world>
This is extended help text.
It can contain multiple lines.
And paragraphs.
SH
}
This spec does the same as the previous spec, but with a multi-line extended description instead of a multi-line usage comment.
Now onto the command file itself.
Code
First few lines of code are almost too obvious to repeat at this point:
#!/usr/bin/env bash
#
# Summary: Display help for a command
#
# Usage: rbenv help [--usage] COMMAND
#
# Parses and displays help contents from a command's source file.
#
# A command is considered documented if it starts with a comment block
# that has a `Summary:' or `Usage:' section. Usage instructions can
# span multiple lines as long as subsequent lines are indented.
# The remainder of the comment block is displayed as extended
# documentation.
set -e
[ -n "$RBENV_DEBUG" ] && set -x
As usual, we have:
- The bash shebang
- The usage summary and description
- The “exit on first error” setting
- The “set verbose mode when RBENV_DEBUG is passed” setting
Completions
Next few lines of code:
# Provide rbenv completions
if [ "$1" = "--complete" ]; then
echo --usage
exec rbenv-commands
fi
Here again is our list of completions. We have a bespoke completion (aka --usage) specific to the help command, and then we print out all possible rbenv commands via the rbenv-commands command, because any rbenv command is also a valid argument to “rbenv help”.
Defining the command_path() function
Next few lines of code:
command_path() {
local command="$1"
command -v rbenv-"$command" || command -v rbenv-sh-"$command" || true
}
Here we define a function named command_path. It sets a variable named command, which is scoped locally to the function, and is set to the value $1, meaning it’s the first argument provided to the function.
Then we do the following:
command -v rbenv-"$command" || command -v rbenv-sh-"$command" || true
We’ve seen this before- we first use command -v to find the path of a command named rbenv-$command, and send that to STDOUT. For example, if we call command_path foo, we’d first check for the path of a command named rbenv-foo. If there’s no command by that name, we try to find the path of a command named rbenv-sh-foo. If that’s not found either, we simply send true to stdout.
The extract_initial_comment_block function
Next block of code:
extract_initial_comment_block() {
sed -ne "
/^#/ !{
q
}
s/^#$/# /
/^# / {
s/^# //
p
}
"
}
Another function definition here, this time it’s called extract_initial_comment_block. This function calls the sed command with the -ne flag, and passes a multi-line string.
What is the purpose of sed?
To learn more about this command, I start with the man entry:
The `sed` utility reads the specified files, or the standard input
if no files are specified, modifying the input as specified by a list
of commands. The input is then written to the standard output.
Although this definition is pretty abstract, luckily there’s also a list of examples of how the command can be used:
EXAMPLES
Replace 'bar' with 'baz' when piped from another command:
echo "An alternate word, like bar, is sometimes used in examples." | sed 's/bar/baz/'
Using backlashes can sometimes be hard to read and follow:
echo "/home/example" | sed 's/\/home\/example/\/usr\/local\/example/'
Using a different separator can be handy when working with paths:
echo "/home/example" | sed 's#/home/example#/usr/local/example#'
Replace all occurances of 'foo' with 'bar' in the file test.txt, without creating a backup of the file:
sed -i '' -e 's/foo/bar/g' test.txt
That’s a bit better. I try my own example in the terminal and verify it works as expected:
$ echo "foo bar baz" | sed "s/foo/quox/"
quox bar baz
I continue Googling to get a bit more context. The command’s usage inside rbenv-help looks complicated, so I think it’ll pay to become a bit more familiar with it.
The site HowToGeek says the following:
The
sedcommand is a bit like chess: it takes an hour to learn the basics and a lifetime to master them (or, at least a lot of practice)…
sedis a stream editor that works on piped input or files of text. It doesn’t have an interactive text editor interface, however. Rather, you provide instructions for it to follow as it works through the text.With sed you can do all of the following:
- Select text
- Substitute text
- Add lines to text
- Delete lines from text
- Modify (or preserve) an original file
…
Substitutions are probably the most common use of
sed.
What do the flags do?
HowToGeek clarifies what the -n flag does:
By default, sed prints all lines. We’d see all the text in the file with the matching lines printed twice. To prevent this, we’ll use the -n (quiet) option to suppress the unmatched text.
ComputerHope, which I’ve often found to be another good resource during this project, adds the following:
The sed stream editor performs basic text transformations on an input stream (a file, or input from a pipeline). While in some ways similar to an editor which permits scripted edits (such as ed), sed works by making only one pass over the input(s), and is consequently more efficient. But it is sed’s ability to filter text in a pipeline which particularly distinguishes it from other types of editors.
I’m still a bit unclear on the -e flag, however. When I Google ‘what does the “-e” flag do sed’, the first result I see is a StackExchange post which proves helpful:
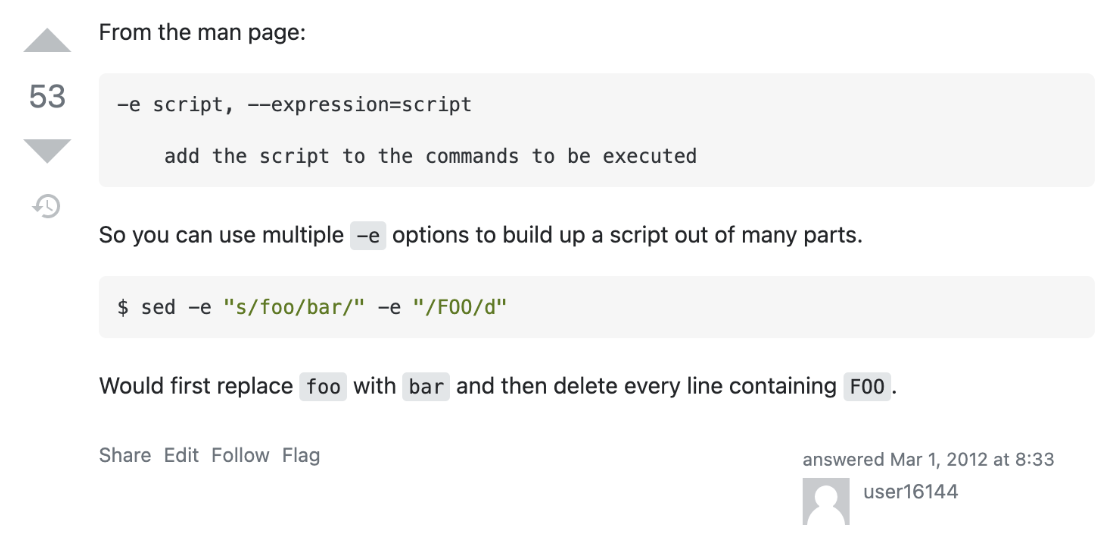
From this and other answers in the post, I can see that -e tells sed to use the subsequent argument (i.e. the strange-looking syntax starting with /^#/ !{) as a script to run against the input that it receives.
To figure out what input we’ll pass to sed, I search the file to see where the extract_initial_comment_block function is called. I see here that we send sed the content of a file (whose name we do not yet know), and then pipe the output of sed to another function named collect_documentation (also TBD).
What does the sed script do?
Looking at the sed script itself, the syntax is hard to parse:
/^#/ !{
q
}
s/^#$/# /
/^# / {
s/^# //
p
}
It appears to be 3 scripts in one, separated by newlines. I ask StackExchange for help and the next day, I have my answer.
The TL;DR is that I was right in thinking that the code inside the quotes represents 3 commands passed to sed, executed one-after-another:
- The 1st command says that if a line is encountered which does not start with a
#symbol, quit thesedcommand entirely. - The 2nd command says that if a line is encountered which starts and ends with the same
#symbol (i.e. it’s just a one-character line containing#), to replace that lone character with a#(i.e.#plus a space). - The 3rd command says that, if a line is encountered starting with
#plus a space, to print that line (not including the#-spacecharacters).
So to summarize what the extract_initial_comment_block function does: it simply prints out the comments that we have frequently encountered at the top of the command files, deleting any # characters at the beginning of each line and stopping after the first line it finds that doesn’t begin with the # character.
This is pretty much what we might expect from a function named extract_initial_comment_block, given what we know about RBENV’s command files so far.
For more on how to use sed, check out LinuxHint.com’s “50 sed command examples” post.
The collect_documentation function
Next few lines of code:
collect_documentation() {
...
}
The collect_documentation function is pretty big, and uses another new command called awk that is both unfamiliar and complicated. So I’ll break it up into pieces.
Declaring and initializing the local awk variable
First block of code:
local awk
awk="$(type -p gawk awk 2>/dev/null | head -n1)"
We declare a local variable named awk. I happen to know there’s a shell utility by the same name, so I imagine we’ll be passing this variable to that command at some point. We assign a value to our local variable awk, and that value is $(type -p gawk awk 2>/dev/null | head -n1).
We’ve seen type -p before, when deciding whether to use greadlink or readlink to find a command. It returns the path to a command, but only if that command lives in a disk file somewhere. If the command is (for example) a shell function, type -p will return nothing.
In the case of setting our local awk variable, type -p gawk awk searches the disk for the files associated with 2 commands, gawk and awk. It pipes the results to head -n1, which means it takes the first filepath it finds from those 2 commands, and it pipes any errors to /dev/null. So the value of the awk local variable is either the filepath for the gawk command or that of the awk command (if no filepath was found for gawk).
According to the Github history, the reason we check for gawk first and then fall back to awk is because the Solaris version of UNIX implements awk in a way which broke rbenv-help.
Erroring out if no awk command
Next block of code:
if [ -z "$awk" ]; then
echo "rbenv: cannot find awk" >&2
return 1
fi
If neither gawk nor awk is installed on the user’s system, we echo an error message to STDERR and return a non-zero exit code. This might happen if (for example) a user is running RBENV on a version of Windows with which Bash does not natively ship. Note that Bash is now available for Windows, but that hasn’t always been the case.
Disabling a shellcheck rule
Next line of code:
# shellcheck disable=SC2016
I Google “what is ShellCheck”, and the first result of this search describes it as “ShellCheck is an open source static analysis tool that automatically finds bugs in your shell scripts.” Back to the line of code, it appears that shellcheck disable=SC2016 disables rule number 2016:
Expressions don’t expand in single quotes, use double quotes for that.
Problematic code:
name=World echo 'Hello $name' # Outputs Hello $nameCorrect code:
name=World echo "Hello $name" # Outputs Hello WorldRationale: ShellCheck found an expansion like $var, $(cmd), or
cmdin single quotes.Single quotes express all such expansions. If you want the expression to expand, use double quotes instead.
The next line of code includes the beginning of a single-quoted, multi-line string containing a series of commands passed to awk. Normally, running ShellCheck against that line of code would trigger rule # 2016. The RBENV team didn’t want that to happen, so they added an annotation to disable this check, just for that one block of code.
Invoking awk with its first command
That block of code starts out like this:
"$awk" '
We first see "$awk" followed by the opening single-quote. "$awk" is the expansion of the variable we stored a few lines of code earlier, the result of our type -p command. It will expand to either gawk or awk, whichever the user has installed. When it’s expanded, it will be automatically called by the shell.
The awk command
GNU has a user’s guide on the awk utility, which says that it’s “a program that you can use to select particular records in a file and perform operations upon them.” The Linux man page for awk has more details:
The awk utility shall execute programs written in the awk programming language, which is specialized for textual data manipulation. An awk program is a sequence of patterns and corresponding actions. When input is read that matches a pattern, the action associated with that pattern is carried out.
This sounds kind of similar to how sed is used, actually.
The guide continues:
Input shall be interpreted as a sequence of records. By default, a record is a line, less its terminating
, but this can be changed by using the `RS` built-in variable. Each record of input shall be matched in turn against each pattern in the program. For each pattern matched, the associated action shall be executed.
More similarities to sed:
- each record is a line from the input
- each record is matched against a specified pattern.
- for each matching record, the corresponding behavior specified in the command is performed.
TODO: come up with a guide on how to do some common operations using sed, and again using awk. Compare which tool is best for which operations.
I’ve decided that the easiest way to understand the subsequent sequence of awk commands is to ask ChatGPT what the script does, and then do a series of experiments to test whether ChatGPT led me astray or not. Here’s the initial question I asked, followed by the initial answer. I’ll be diving deeper into each part of the answer in follow-up questions.
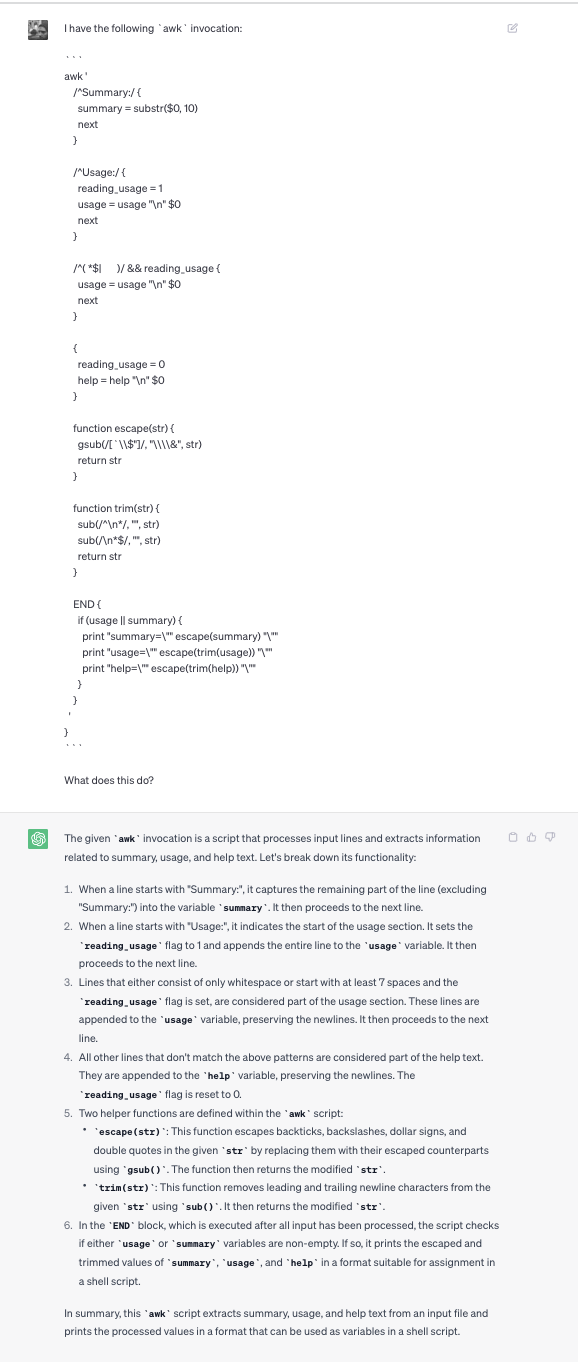
My question to ChatGPT was:
I have the following
awkinvocation:
awk '
/^Summary:/ {
summary = substr($0, 10)
next
}
/^Usage:/ {
reading_usage = 1
usage = usage "\n" $0
next
}
/^( *$| )/ && reading_usage {
usage = usage "\n" $0
next
}
{
reading_usage = 0
help = help "\n" $0
}
function escape(str) {
gsub(/[`\\$"]/, "\\\\&", str)
return str
}
function trim(str) {
sub(/^\n*/, "", str)
sub(/\n*$/, "", str)
return str
}
END {
if (usage || summary) {
print "summary=\"" escape(summary) "\""
print "usage=\"" escape(trim(usage)) "\""
print "help=\"" escape(trim(help)) "\""
}
}
'
}
What does this do?
And ChatGPT’s response:
The given
awkinvocation is a script that processes input lines and extracts information related to summary, usage, and help text. Let’s break down its functionality:When a line starts with “Summary:”, it captures the remaining part of the line (excluding “Summary:”) into the variable
summary. It then proceeds to the next line.When a line starts with “Usage:”, it indicates the start of the usage section. It sets the
reading_usageflag to 1 and appends the entire line to theusagevariable. It then proceeds to the next line.Lines that either consist of only whitespace or start with at least 7 spaces and the
reading_usageflag is set, are considered part of the usage section. These lines are appended to theusagevariable, preserving the newlines. It then proceeds to the next line.All other lines that don’t match the above patterns are considered part of the help text. They are appended to the
helpvariable, preserving the newlines. Thereading_usageflag is reset to 0.Two helper functions are defined within the
awkscript:
escape(str): This function escapes backticks, backslashes, dollar signs, and double quotes in the givenstrby replacing them with their escaped counterparts using gsub(). The function then returns the modifiedstr.
trim(str): This function removes leading and trailing newline characters from the givenstrusingsub(). It then returns the modifiedstr.In the
ENDblock, which is executed after all input has been processed, the script checks if eitherusageorsummaryvariables are non-empty. If so, it prints the escaped and trimmed values ofsummary,usage, andhelpin a format suitable for assignment in a shell script.In summary, this
awkscript extracts summary, usage, and help text from an input file and prints the processed values in a format that can be used as variables in a shell script.
So this function:
- reads the comments that were redirected to it from the extracted comment blocks,
- stores them in variables named
summary,usage, orhelpdepending on which section of the comments they appeared in, and - prints a script to
stdoutwhich creates shell variables with the same names and contents as theawkvariables.
We’ll see later on that the Bash code which is output by collect_documentation is later eval‘ed by multiple other functions, defined further down in the file.
So that’s a high level of what this function does.
I find this link from The Linux Documentation Project, which walks through how to use awk:
Awk breaks each line of input passed to it into fields. By default, a field is a string of consecutive characters delimited by whitespace, though there are options for changing this. Awk parses and operates on each separate field. This makes it ideal for handling structured text files – especially tables – data organized into consistent chunks, such as rows and columns.
Strong quoting (i.e. single quotes) and curly brackets enclose blocks of awk code within a shell script.
Let’s do some experiments to see how awk works, after which we’ll be able to better understand how it achieves the above.
Experiments
Basic awk usage w/ echo
I see this example in the above TLDP link:
# $1 is field #1, $2 is field #2, etc.
echo one two | awk '{print $1}'
# one
echo one two | awk '{print $2}'
# two
# But what is field #0 ($0)?
echo one two | awk '{print $0}'
# one two
# All the fields!
I successfully reproduce the behavior of the exact same commands in my Bash terminal:
bash-3.2$ echo one two | awk '{print $1}'
one
bash-3.2$ echo one two | awk '{print $2}'
two
bash-3.2$ echo one two | awk '{print $0}'
one two
Using awk with input from a file
The same TLDP example contains the following code:
awk '{print $3}' $filename
# Prints field #3 of file $filename to stdout.
awk '{print $1 $5 $6}' $filename
# Prints fields #1, #5, and #6 of file $filename.
awk '{print $0}' $filename
# Prints the entire file!
# Same effect as: cat $filename . . . or . . . sed '' $filename
I make my own text file named foo containing the following text:
foo bar baz
bar baz buzz
baz buzz quox
I then run the following:
bash-3.2$ awk '{print $3}' foo
baz
buzz
quox
I do in fact see the 3rd field from each line of text in the input file. This shows that we’re applying the same awk rule (i.e. '{print $3}') to each line of the input file.
Variables in awk- initializing the var in the script
I don’t really like the last example in the TLDP link, so I ask ChatGPT for a simple example of how to use variables in awk:
Can you give me a very simple example of using a variable in an
awkscript?
The answer I get is pretty clear:
Let’s say we have a file called
numbers.txtwith the following content:1 2 3 4 5And we want to calculate the sum of these numbers using an
awkscript. We can use a variable to accumulate the sum. Here’s the script, stored in a file namedsum.awk:{ sum += $1 } END { print "Sum:", sum }Now, if we run the script with the
numbers.txtfile as input:awk -f sum.awk numbers.txtThe output will be:
Sum: 15Let’s break down the script:
sum += $1: This line is the main action of the script. It adds the value of the first field ($1) to the variable sum. The first field refers to the value in the current line being processed.
END: This keyword denotes the beginning of the END block, which is executed after all input lines have been processed.
print “Sum:”, sum: In the END block, this line prints the string “Sum:” followed by the value of the sum variable.
In this example, the variable sum is initialized to 0 implicitly. For each line in the input file, the value of the first field is added to the sum variable. Finally, in the END block, the script prints the accumulated sum.
I try this in my Bash terminal, and get the same output:
bash-3.2$ awk -f sum.awk numbers.txt
Sum: 15
This example showed that variables can be initialized in an earlier round of parsing lines, and re-used in subsequent rounds of parsing lines. It also showed how to use the END keyword to execute a one-time block of logic after all the lines of input have been processed.
Variables in awk- passing in a variable using -v
I modify the last command I executed, adding the flag -v sum=5 like so:
bash-3.2$ awk -v sum=5 -f sum.awk numbers.txt
Sum: 20
I initialized the sum variable to start at 5, instead of relying on awk to implicitly initialize the variable to 0. When I did this, the final value of sum was 5 higher than it was before.
Executing an awk rule only on certain lines
We can choose to optionally execute an awk action only when certain conditions are met. This is called a “pattern-action pair”. For example, according to ChatGPT, if we want to print only the lines from our numbers.txt file which are even, we can do the following:
awk '{ if ($1 % 2 == 0) { print $0 } }' numbers.txt
I successfully reproduce the above in my terminal:
bash-3.2$ awk '{ if ($1 % 2 == 0) { print $0 } }' numbers.txt
2
4
Using the next keyword to skip certain lines
According to ChatGPT:
The next keyword is used in awk to skip the execution of any further rules or actions for the current line of input and immediately move on to the next line. It effectively allows you to control the flow of processing within the awk script.
Here’s how the next keyword works in a series of awk commands:
When awk reads a line of input, it evaluates each rule or action in the script in the order they appear.
If the next keyword is encountered within a rule or action, it immediately terminates the processing of the current line and proceeds to the next line.
No further rules or actions are executed for the current line. The next line is then processed from the beginning of the script.
The next keyword is often used to optimize awk scripts and avoid unnecessary processing.
We can use the next keyword along with our numbers.txt input file to sum up all the even numbers, and print them out at the end, like so:
awk -v sum=0 -f - "$filename" <<'EOF'
{
if ($1 % 2 == 0) {
sum += $1
}
}
END {
print "Sum:", sum
}
EOF
In the above example, we input the pattern-action pairs via a heredoc. -f - specifies that the awk script should be read from the standard input (heredoc) rather than from a file. The - indicates the standard input.
Running the above results in:
bash-3.2$ awk -v sum=0 -f - "$filename" <<'EOF'
> {
> if ($1 % 2 == 0) {
> sum += $1
> }
> }
>
> END {
> print "Sum:", sum
> }
> EOF
Sum: 6
Defining functions in awk
We can extract the above logic from the action itself, and into a function, and then call our function from inside the rule. That would look something like this:
bash-3.2$ awk -v sum=0 -f - "$filename" <<'EOF'
> function addToSum(num) {
> if (num % 2 == 0) {
> sum += num
> }
> }
>
> {
> addToSum($1)
> }
>
> END {
> print "Sum:", sum
> }
> EOF
Sum: 6
Above, we declare a function called addToSum which takes a number as a parameter. If the number is divisible by 2, we add it to our running sum variable, which we have access to inside of our function. Then, we create a rule where we call addToSum for each line in the input file, passing the first param ($1) as the argument.
In the END step, we print the final value for sum to the terminal. Since we initialize our sum variable to 0 and the even numbers in our series are 2 and 4, our final Sum value is 6.
Using awk’s built-in functions
Let’s say that our numbers.txt file contains some malformed data- occasionally a line will be a letter instead of a number:
1
a
2
b
3
c
4
d
5
e
If the letter is a vowel, we want to replace it with the number 2. Otherwise, we want to ignore it. We can use awk’s sub() function to replace any vowel from field #1 (aka $1) with the number 2:
bash-3.2$ awk -v sum=0 -f - "$filename" <<'EOF'
> function addToSum(num) {
> if (num % 2 == 0) {
> sum += num
> }
> }
>
> {
> sub(/[aeiou]/, 2, $1)
> addToSum($1)
> }
>
> END {
> print "Sum:", sum
> }
> EOF
Sum: 10
This time, we replace the letters a and e with 2, giving us a Sum of 10, or 4 more than our previous Sum of 6.
sub with the & character
Let’s now assume that our input file once again looks like this:
1
2
3
4
5
If a line contains an odd number, we should concatenate a 2 to the end of that number, making it even. For example, the 1 should be replaced with 12. Similarly, the line 3 should be replaced with 32. The rest of the program should behave as before.
Our command will therefore look like this:
awk -v sum=0 -f - "$filename" <<'EOF'
function addToSum(num) {
print "num:", num
if (num % 2 == 0) {
sum += num
}
}
{
print "line:", $0
sub(/[13579]/, "&2", $0)
addToSum($1)
}
END {
print "Sum:", sum
}
EOF
The line…
sub(/[13579]/, "&2", $0)
…means “replace any occurrence of 1, 3, 5, 7, or 9, with the same number, followed by 2.
We’re also printing each input line, before and after this transformation takes place.
When we run this script, we get:
line: 1
num: 12
line: 2
num: 2
line: 3
num: 32
line: 4
num: 4
line: 5
num: 52
Sum: 102
So the line 1 is transformed into 12, and then the number 12 is passed to addToSum(). As a result, our sum is 12+2+32+4+52, or 102.
Notice that the 2nd argument passed to sum was "&2", with &2 wrapped in double-quotes, not regex forward slashes (i.e. /&2/). The latter will result in an error.
The above examples should give us enough knowlege about awk to be able to understand how it’s used in RBENV, but its capabilities go far beyond what we’ve demonstrated here. awk is one of those tools which takes a minute to learn and a lifetime to master. If you want to learn more, GNU maintains an entire manual just on awk here.
Let’s now turn to the collect_documentation function. We start with this pattern-action pair:
/^Summary:/ {
summary = substr($0, 10)
next
}
The pattern is:
/^Summary:/
And our action is:
{
summary = substr($0, 10)
next
}
This means we initialize the summary variable and store the substr($0, 10) value inside of it when the given line of input starts with Summary:. According to the GNU guide to awk, the substr built-in function takes an input string and a character position number (1-based, not 0-based), and returns all the characters from the specified position number until the end of the string.
You can optionally provide a 3rd argument, the length N of characters you want to check, and substr will return a string starting at your position number and spanning the N subsequent characters (inclusive of the starting character).
The last thing we do in this rule is skip to the next line of input, without falling through to any subsequent pattern-action pairs.
Next rule:
/^Usage:/ {
reading_usage = 1
usage = usage "\n" $0
next
}
If the line starts with the string Usage:, we initialize the reading_usage variable to 1 and either initialize the variable to equal the entire line, or concatenate the entire line to the existing value of usage, with a newline separating the previous value of usage and the value of the current line.
The last thing we do in this rule is skip to the next line of input, without falling through to any subsequent pattern-action pairs.
Next block of code:
/^( *$| )/ && reading_usage {
usage = usage "\n" $0
next
}
If the reading_usage variable has been set and the current line either starts with 7 spaces or consists entirely of spaces, we concatenate a newline and the current line of input to the usage variable.
This is the same action we took on the previous rule, except we don’t need to set reading_usage to 1 because we already know it’s equal to 1 (because of the && reading_usage check).
The last thing we do in this rule is skip to the next line of input, without falling through to any subsequent pattern-action pairs.
Next block of code:
{
reading_usage = 0
help = help "\n" $0
}
If we reach this rule, we know that we’re no longer working with summary or usage data, so we set reading_usage equal to 0 and either create a new variable called help (if it didn’t already exist) or concatenate a newline and the current line of input to the existing value of help.
This is the last rule, so then we either move on to the next line of input, or (if there are no more lines of input) execute the END block.
Next block of code:
function escape(str) {
gsub(/[`\\$"]/, "\\\\&", str)
return str
}
We define a function called escape, which calls gsub (a function that is similar to sub, but operates on every occurrence of the regex pattern, not just the first one it finds).
What is the pattern that we’re matching against? I find regular expressions hard to read, so to save time, I ask ChatGPT to translate this for me. It tells me that the 1st argument to gsub is this:
/[`\\$"]/
This regular expression will match any occurrence of the following characters:
` \ $ "
The 2nd argument to gsub is:
"\\\\&"
This was pretty confusing for me, so I decided to do an experiment.
Experiment- why so many backslashes?
I create a file named escape.awk, which I will use as the command when I run awk:
function escape(str) {
gsub(/[`\\$"]/, "&", str)
return str
}
{
print escape($0)
}
Notice there are no \ characters in the 2nd param to gsub.
Then I create a text file named “file.txt” and containing the following:
` foo
$ bar
" baz
\ buzz
I then run the following in my terminal:
$ awk -f escape.awk file.txt
` foo
$ bar
" baz
\ buzz
I get the same output as the original input.
Then I add a single \ character in front of &:
function escape(str) {
gsub(/[`\\$"]/, "\&", str)
return str
}
{
print escape($0)
}
When I run the command again, I get:
$ awk -f escape.awk file.txt
` foo
$ bar
" baz
\ buzz
I then add another \ and re-run the command:
$ awk -f escape.awk file.txt
& foo
& bar
& baz
& buzz
This time the output is different- a & character everywhere, instead of the original characters.
I add another \ and see the same thing:
$ awk -f escape.awk file.txt
& foo
& bar
& baz
& buzz
Finally, I add a fourth \, and see:
$ awk -f escape.awk file.txt
\` foo
\$ bar
\" baz
\\ buzz
Now it’s back to the original characters, but this time with a \ before each one. So 4 backslashes in the 2nd argument to gsub is the minimum number of backslashes needed for the output to show a single backslash, plus the original character. Based on this function’s name (escape()), that sounds like what we want.
Skipping ahead a bit to the END block, we see that the output of collect_documentation is a series of commands printed to stdout, which assign text values to variables named usage, summary, and help. Those commands will be passed to a call to eval later. Our current function, escape, ensures that any such text values which contain those 4 special characters don’t lose those characters when they’re printed to the screen for the user to read.
Next block of code:
function trim(str) {
sub(/^\n*/, "", str)
sub(/\n*$/, "", str)
return str
}
This function is much more straightforward. We check for one or more newline characters (\n) at the beginning of the line, and then again at the end of the line, and delete any that we find.
Next block of code:
END {
if (usage || summary) {
print "summary=\"" escape(summary) "\""
print "usage=\"" escape(trim(usage)) "\""
print "help=\"" escape(trim(help)) "\""
}
}
We’ve reached the END block of our call to awk. We print a series of strings which represent shell commands, specifically commands which store string values in variables named summary, usage, and help. The output might look something like this:
summary="Display the version of rbenv"
usage=""
help="Displays the version number of this rbenv release, including the
current revision from git, if available.
The format of the git revision is:
<version>-<num_commits>-<git_sha>
where `num_commits` is the number of commits since `version` was
tagged."
These variables will be used later in the code for rbenv help.
Calling extract_initial_comment_block and collect_documentation
Next block of code:
documentation_for() {
local filename
filename="$(command_path "$1")"
if [ -n "$filename" ]; then
extract_initial_comment_block < "$filename" | collect_documentation
fi
}
We define a function named documentation_for. In its body, we declare a local variable named filename, and set it equal to the filepath of the command we pass to documentation_for when we call it. The filepath comes from the command_path function we defined earlier.
If filename is non-empty, we pass the filename to the extract_initial_comment_block function that we previously examined. From this, we get the raw comment lines at the head of the file, (minus the comments’ # symbols), and we pass the result to collect_documentation.
So the return value of something like documentation_for "global" would be the above variable assignment text (i.e. summary: Set or show the global Ruby version) for the rbenv global command.
Printing just the summary text
Next block of code:
print_summary() {
local command="$1"
local summary usage help
eval "$(documentation_for "$command")"
if [ -n "$summary" ]; then
printf " %-9s %s\n" "$command" "$summary"
fi
}
We define a function named print_summary. Inside of that function, we:
- create a local variable named
commandand set it equal to the first argument passed to this function. - then create 3 more local variables, called
summary,usage, andhelp. - then run
documentation_foron ourcommandvariable, andevalthe result (which should be thesummary=.../usage=..../help=...lines of text) in order to populate values in the local variables we just declared.
If our summary variable is non-empty, we print just the contents of that variable; since this function is called print_summary, that’s all we want to do here.
Printing summaries for all requested commands
Next block of code:
print_summaries() {
for command; do
print_summary "$command"
done
}
Another definition for a function, this one called print_summaries. This just iterates over all the commands that the user passed in as arguments, and calls the previous print_summary function on each one.
We’ll see later that this function is called if the user just types rbenv help, with no specific command as an argument.
Printing just the help docs
Next block of code:
print_help() {
local command="$1"
local summary usage help
eval "$(documentation_for "$command")"
[ -n "$help" ] || help="$summary"
if [ -n "$usage" ] || [ -n "$summary" ]; then
if [ -n "$usage" ]; then
echo "$usage"
else
echo "Usage: rbenv ${command}"
fi
if [ -n "$help" ]; then
echo
echo "$help"
echo
fi
else
echo "Sorry, this command isn't documented yet." >&2
return 1
fi
}
This is another function definition, but a big one. So we’ll break it up further into shorter snippets.
First off:
local command="$1"
local summary usage help
The first few lines of this function work the same way as those of print_summary:
- We declare 4 local vars (called
command,summary,usage, andhelp), and initializecommandto be the first argument passed toprint_help. - We then
evalthe return value ofdocumentation_for $command. - That return value is the
summary=...,usage=..., etc., so callingevalon that multi-line string has the effect of initializing the remaining 3 valueless variables with their values.
The next line:
[ -n "$help" ] || help="$summary"
This says that, if the help variable already has a value, we do nothing. If it’s empty, we initialize it to be the same value as summary.
Next line:
if [ -n "$usage" ] || [ -n "$summary" ]; then
If either our usage or summary variable have values, then we execute the following block of code.
Next:
if [ -n "$usage" ]; then
echo "$usage"
else
echo "Usage: rbenv ${command}"
fi
If the usage variable has a value (i.e. if this command has usage documentation), then we echo those docs. Otherwise, we echo the string Usage: rbenv plus the name of the command.
Next block of code:
if [ -n "$help" ]; then
echo
echo "$help"
echo
fi
If the help variable is non-empty, we echo its value, surrounded by a newline both before and after.
Last block of code for our print_help function:
else
echo "Sorry, this command isn't documented yet." >&2
return 1
fi
If neither the usage nor the summary variables have values, we print an error message to STDERR and return a non-zero exit status.
That’s it for the print_help function!
Printing just the usage docs
Next block of code:
print_usage() {
local command="$1"
local summary usage help
eval "$(documentation_for "$command")"
[ -z "$usage" ] || echo "$usage"
}
The first 3 lines should look familiar- we instantiate and populate 4 local variables, named command, summary, usage, and help. Then, if usage contains a value, we print it to STDOUT.
Re-using the usage variable for something else
Next block of code:
unset usage
if [ "$1" = "--usage" ]; then
usage="1"
shift
fi
- First we unset the
usagevariable if it has already been set, to guarantee that it’s empty. - If the first argument to
rbenv helpis--usage, we set the value of theusagevariable to “1”. - We then remove that first argument from the list of shell arguments, leaving us with a new first argument (which is accessed in the next block of code).
Printing general help docs
Next block of code:
if [ -z "$1" ] || [ "$1" == "rbenv" ]; then
echo "Usage: rbenv <command> [<args>]"
[ -z "$usage" ] || exit
echo
echo "Some useful rbenv commands are:"
print_summaries commands local global shell install uninstall rehash version versions which whence
echo
echo "See \`rbenv help <command>' for information on a specific command."
echo "For full documentation, see: https://github.com/rbenv/rbenv#readme"
If [ -z "$1" ] is true, that means the first argument is empty. This, in turn, means either the user typed rbenv help without arguments, or they typed rbenv help --usage and the --usage argument was shifted off in the previous block of code.
If that’s the case, or if the first argument to rbenv help was rbenv (i.e. the user typed rbenv help rbenv), we do the following:
- First, we echo a general usage instruction that applies to all rbenv commands.
- Then, if we set the value of
usagein the preiousifblock, we exit. - Otherwise, if that variable is currently empty, we echo summaries for a hard-coded list of rbenv commands (the line
print_summaries commands local global shell install...). - We also print some additional hard-coded strings before and after the summaries.
Printing help docs for a specific command
Next block of code:
else
command="$1"
if [ -n "$(command_path "$command")" ]; then
if [ -n "$usage" ]; then
print_usage "$command"
else
print_help "$command"
fi
else
echo "rbenv: no such command \`$command'" >&2
exit 1
fi
fi
This is the else block for our previous if condition. If that condition is false, that means the user provided an argument to rbenv help which was not “rbenv” itself (i.e. they typed rbenv help plus a specific command like global, local, etc.). In this case, we do the following:
- First, we set the
commandvariable equal to the first argument. - If that command is associated with a file in our
$PATHdirectories, then we either:- print any
usageinstructions for that command (if the user passed the--usageflag and$usagewas re-set), or - print the
helpinstructions for that command.
- print any
- Lastly, if the
ifcheck here (if [ -n "$(command_path "$command")" ]; then) fails, then we echo a “no such command” error message and direct it to STDERR, and we exit with a non-zero status.
A Potential PR?
Remember that the print_help method specifies that we only print help instructions if either summary or usage instructions also exist:
print_help() {
local command="$1"
local summary usage help
eval "$(documentation_for "$command")"
[ -n "$help" ] || help="$summary"
if [ -n "$usage" ] || [ -n "$summary" ]; then # here
if [ -n "$usage" ]; then # and here
echo "$usage"
else
echo "Usage: rbenv ${command}"
fi
if [ -n "$help" ]; then
echo
echo "$help"
echo
fi
else
echo "Sorry, this command isn't documented yet." >&2
return 1
fi
}
So I think this means that we may have some redundant if conditions. For example:
if [ -n "$usage" ]; then
print_usage "$command"
else
print_help "$command"
fi
If we reach the print_help call above, that means $usage is empty. So we shouldn’t need the 2 if [ -n "$usage" ] checks inside print_help (indicated by the #here comments above). If those are indeed superfluous, removing them would make the code cleaner and easier to read. Could be a good candidate for a PR.
That’s it for this command! On to the next one.